

Sverige har en relativt lång tradition av att skapa en typ av korpus som brukar kallas trädbank. En trädbank är en samling texter som har annoterats (märkts upp) med ordklasser och syntaktisk struktur. Den syntaktiska strukturen för en mening kan ritas upp så att den liknar ett träd. Trädbanken Talbanken skapades redan på 70-talet (Teleman, 1974) och texterna (och delar av annoteringen) har återanvänts i flera trädbanker sedan dess. Trädbankerna kan sedan t ex användas för att studera grammatiska frågor, för att lättare hitta information i stora textmängder, eller för att lära datorprogram att automatiskt märka upp nya texter med syntaktisk annotering.
Det finns, grovt sett, två olika sorters syntaktisk annotering. Den ena är frasstruktur, som kopplar samman ord i fraser (som nominalfras och verbfras). Här är ordföljden viktig, eftersom olika ordföljd ger olika syntaktisk struktur. Få svenska trädbanker har dock ren frasstruktur. Den andra syntaktiska modellen är dependensstruktur, som fokuserar på ordens relation till varandra, deras syntaktiska funktion. Denna syntaktiska struktur används för korpusar i Korp i dagsläget. En av de vanligare modellerna för dependensannotering är Universal Dependencies, som har använts för trädbanker i runt 100 språk (se t ex Nivre m fl, 2016). Utöver dessa två typer finns det s.k. hybridmodeller, som kombinerar frasstruktur med syntaktisk funktion. En sådan modell utvecklades av Skut m fl (1997) och trädbanken Eukalyptus har denna typ av syntaktiska beskrivning.
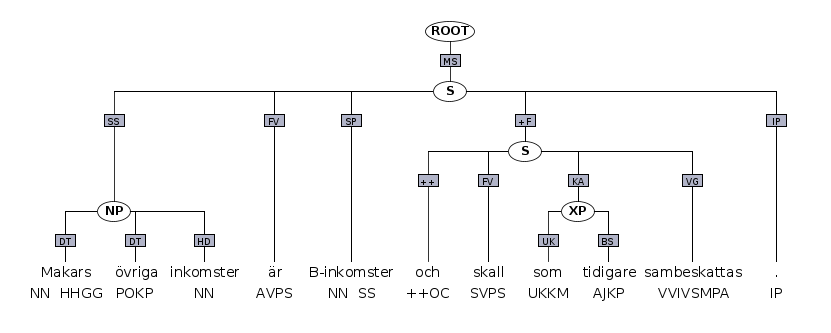

I Eukalyptus används primärbågar för att koppla samman ord till fraser (noder), som i sin tur knyts ihop så att man får en toppnod, en fras som omfattar alla ord i meningen. Utöver detta använder man sekundärbågar för att lägga till extra information, som t ex ord eller fraser vars funktion delas mellan flera fraser. En fras måste inte bestå av ord som följer på varandra, utan kan vara s.k. diskontinuerlig. Det betyder att skillnader i ordföljd inte måste leda till olika syntaktiska strukturer. En fördel med detta format är också att det relativt enkelt går att omvandla till en ren frasstruktur eller dependensstruktur. Det är viktigt för oss eftersom språkteknologer ofta är intresserade av syntaktiska funktioner, medan språkvetare och nordister ofta pratar om syntax i termer av fraser.

I bilden ser vi ett exempel på en annoterad mening i trädbanken Eukalyptus. Under orden ser vi att varje ord har märkts upp med en av tretton ordklasser och morfologisk information. Flera av orden har också annoterats med betydelse, som länkar till betydelser i vårt huvudlexikon Saldo.
Ovanför orden ser vi att orden knyts direkt till en av tio fraskategorier (de som slutar på P, samt S (för Satz eller sentence) som omfattar en hel mening). Dessutom har vi flerordsenheter (de som slutar på M), som får sitt kategorinamn från ordklasserna, men delvis liknar fraser. I den syntaktiska strukturen markeras primärbågar med raka streck och sekundärbågar med vågade streck. Varje båge får en av 22 bågetiketter, som markerar syntaktisk funktion. Vissa ordenheter, som skiljetecken, är inte del av den syntaktiska strukturen.
Vilken kategori en fras tillhör (dvs vilken etikett den tilldelas) avgörs av frasens huvud (bågetikett HD). Så i en nominalfras (NP) är huvudet ett nominal, vanligen t ex ett substantiv eller pronomen, i en prepositionsfras (PP) är huvudet en preposition, och i en verbfras (VP) ett verb. Fraser får maximalt ha ett huvud, och detta huvud måste vara ett ord (eller ett flerordsuttryck). I ett begränsat antal fall tillåts att man bryter mot dessa regler kring huvudet. Ett exempel på ett sådan fall är samordningsfrasen (KoP) 'bombexplosioner och mord', eftersom en samordning kan ha flera samordnare (KO). Här markerar vi istället samordnaren som pseudohuvud (PH).
Sammantaget hoppas vi att den syntaktiska annoteringen i Eukalyptus ger en bra grund för både språkteknologisk och språkvetenskaplig forskning på svenska texter. Nästa steg blir att lära ett datorprogram den här typen av syntaktisk struktur, så att vi kan annotera fler texter i Korp automatiskt.
Referenser och mer att läsa
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Yoav Goldberg, Jan Hajič, Christopher D. Manning, Ryan McDonald, Slav Petrov, Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty och Daniel Zeman. Universal Dependencies v1: A Multilingual Treebank Collection. I Proceedings of LREC, 2016.
Wojciech Skut, Brigitte Krenn, Thorsten Brants och Hans Uszkoreit. An annotation scheme for free word order languages. I Proceedings of the 5th Conference on Applied Natural Language Processing, 1997.
Ulf Teleman. Manual för grammatisk beskrivning av talad och skriven svenska. Studentlitteratur, Lund, 1974.
En mer detaljerad beskrivning av den syntaktiska strukturen i Eukalyptus (på engelska) finns här:
Yvonne Adesam, Gerlof Bouma, and Richard Johansson. Defining the Eukalyptus forest -- the Koala treebank of Swedish. I Proceedings of the 20th Nordic Conference of Computational Linguistics (NODALIDA 2015), 2015.
https://www.aclweb.org/anthology/W15-1804.pdf
Korpusen Eukalyptus (i en tidig version med flera kända fel) finns att ladda ner här:
https://spraakbanken.gu.se/resurser/eukalyptus
Tidigare relaterade blogginlägg:
Om ordklasser för svenska språket
The five lives of Talbanken